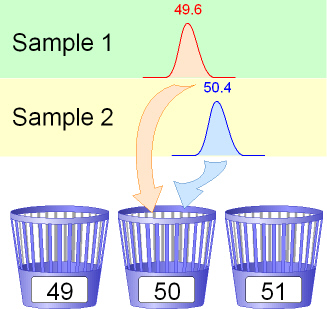
Bin
A bin is equivalent to a peak in a trace curve or a band in a gel image. It holds
data values around a local maximum of a single sample. It has a certain
width in data points and after sizing also a width in base sizes.
It comprises data points with the highest data points usually forming a local
maximum near the center. The sum of all data point values is the area.
The base size of a bin should be an integer value because DNA chains can
only deviate from each other by the addition or deletion of a single nucleotide.
In reality the base size is a float number. This is due to the inaccurateness of
biological data.
Bins that below the smallest or beyond the highest size standard fragment
should not be considered for further analysis because they cannot be sized
exactly (a limitation of the local southern algorithm).
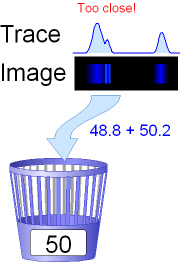
Superbin
Sometimes two or more bins of the same sample (trace peaks/image bands)
are too close to each other to form individual bins. In this case the individual
bins are united in a superbin. So a superbin is a container for bins located
closely together.
An example:
A sample has two peaks sized with 79.6 and 80.2. They are 0.6 bases apart
from each other. Because DNA fragments can differ in a minimum of a single
base in length, these peaks may not be treated as separate fragments. If the
values are rounded we obtain 80 for both. So a clear decision is difficult.
Therefore we define a superbin comprising the two bins.
Hyperbin
A hyperbin is a container for bins and superbins of two or more samples.
If several DNA fingerprints are compared it is a good idea to check the
presence of certain peaks in different samples.
Example
One sample has a peak with a size of 83 base pairs ('peak at 83 bp'). This peak
is also present in the second sample but not in the third. The second and third
sample have a common peak with a size of 108 base pairs. And so on. This
can be written as a table:
|
|
Peak at 83 bp
|
Peak at 108 bp
|
...
|
|
Sample #1
|
x
|
|
...
|
|
Sample #2
|
x
|
x
|
...
|
|
Sample #3
|
|
x
|
...
|
|
...
|
...
|
...
|
...
|
So the peaks of individual samples are united in larger containers, the
hyperbins.
How can we build hyperbins?
The basic idea would be to cluster individual sample bins that vary in a range of
±0.5 from a defined base size into the same hyperbin. This hyperbin would
have a width of exactly 1.0.
In reallity it is much more complicated...